Pareto frontier LLMs, Kagi edition
Kagi benchmarks LLMs on a private benchmark. I asked Claude to build a Pareto frontier chart for Kagi’s April 17th, 2025, update (source code).
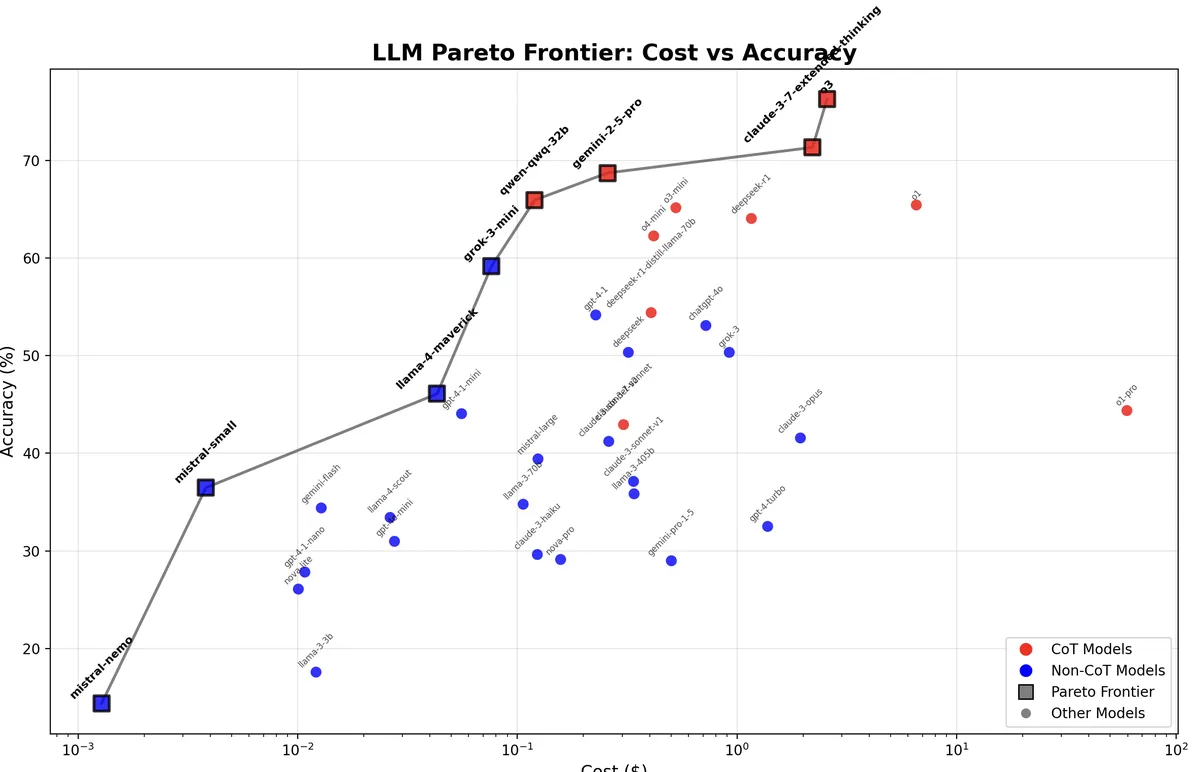
Claude has the strange property of doing well on some benchmarks and not others. It creates half as much slop in longform writing as Gemini and OpenAI models, for example, and does well in a number of coding benchmarks, while doing much worse than other frontier models in other benchmarks.
LLama 4 Maverick is at the frontier, and GPT-4.1-mini is quite close. But GPT-4.1 isn’t near the frontier, which surprised me. It’s much worse than the slightly cheaper Gemini 2.5 Pro.
Here are the 8 frontier models. I also included GPT-4.1-mini, since it’s so close.
| Model | Cost ($) | Accuracy (%) | CoT | Status |
|---|---|---|---|---|
| mistral-small | 0.0038 | 36.47 | No | Frontier |
| llama-4-maverick | 0.0431 | 46.09 | No | Frontier |
| gpt-4-1-mini | 0.0557 | 44.06 | No | Near-Frontier |
| grok-3-mini | 0.0763 | 59.17 | No | Frontier |
| qwen-qwq-32b | 0.1199 | 65.94 | Yes | Frontier |
| gemini-2-5-pro | 0.2570 | 68.72 | Yes | Frontier |
| claude-3-7-extended-thinking | 2.2057 | 71.34 | Yes | Frontier |
| o3 | 2.5719 | 76.29 | Yes | Frontier |
Some notes on generating this graph with AI: Claude generated the graph I wanted in one shot. o4-mini also did a decent job, but I had to ask it to change the cost axis to log scale, which would be obvious to a person. On the other hand, Claude couldn’t run the code, whereas o4-mini did, so I got immediate feedback from o4-mini, but had to copy paste to my editor for Claude. o3 correctly figured out the cost axis should be log scale, but it didn’t label the points. (Later, I asked Claude to color the dots to show CoT vs. non-CoT models.)
Update 2025-05-07: grok-3-mini is in fact a reasoning model. It defaults to low. Kagi confirmed in their Discord to me that there was an error in their table. Intriguingly just from eyeballing the chart it does seem like grok-3-mini is part of a second, reasoning, Pareto frontier, rather than the initial non-reasoning Pareto frontier.